Apple A15 Neural Engine 推理速度超越 Nvidia RTX2080 达 6.7%
最近我看到了苹果发布的一篇博客,其中一张图片展示了 Apple Neural Engine(ANE)的性能。

作为一名 iOS 开发者和技术爱好者,当我看到苹果声称 A15 的 FP16 性能可以接近 16TFLOPS 时,我感到非常震惊。作为对比,RTX 2070 的 FP16 性能为 14.93 TFLOPS。我很好奇 A15 在实际中的表现,于是决定亲自测试一下。
1. Apple Neural Engine(A15)与 RTX 2080 对比
| ANE | ANE | RTX2080 |
|---|---|---|
| FP16 | 15.8TFLOPS | 20.14 TFLOPS |
| FP32 | - | 10.07 TFLOPS |
测试方法
考虑到 ANE 针对卷积网络做了专门优化,而我最近正好用 RealESRGAN_x4plus 开发了 PixAI,因此我将使用 RealESRGAN_x4plus 进行测试。
 如果你想在手机上体验这个模型,可以在这里下载。
如果你想在手机上体验这个模型,可以在这里下载。
模型规格
Real-ESRGAN 旨在开发通用图像/视频修复的实用算法。
| 模型 | 总参数量 | 参数大小 |
|---|---|---|
| RealESRGAN_x4plus | 16,697,987 | 66.79 MB |
模型结构
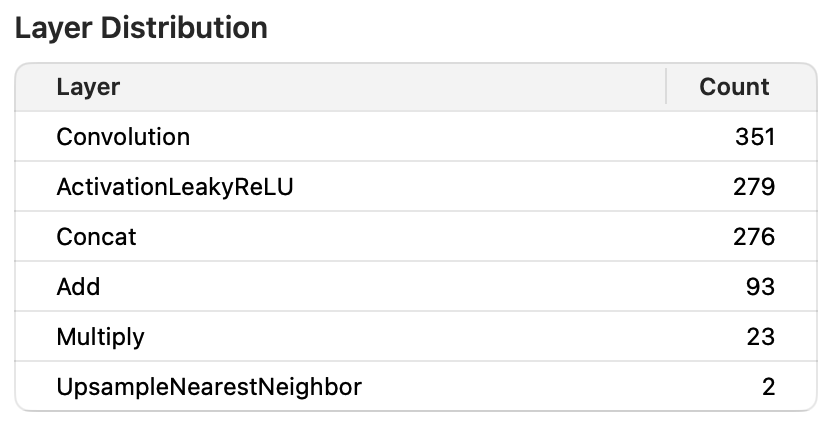
测试方法:
- 输入:1 x 3 x 256 x 256 RGB 图片
- RTX2080:先进行 10 次推理预热,然后循环 100 次推理并计算平均推理时间
- MacBook Pro 2018 2.3 GHz 4C8T Intel Core i5 搭配 Metal GPU 加速
- A15 Neural Engine:使用 Xcode 内置性能测试工具测试平均推理时间
- A15 Metal GPU:同上
那么 A15 芯片在实际中表现如何呢?
本文严格聚焦于性能。关于设计、输入输出、续航等方面,网上有大量其他资源。
2. 开始测试
RTX2080 BatchSize 1 FP32
测试代码:
# 先进行 10 次推理预热,然后循环 100 次推理并计算平均推理时间
with torch.no_grad():
example_input = torch.rand(1,3,256,256,dtype=torch.float32).to("cuda")
esrganWrapper.eval()
for _ in range(0,10):
out = esrganWrapper(example_input)
start = time.time()
for _ in range(0,100):
out = esrganWrapper(example_input)
end = time.time()
avg = (end-start)/100
100 次循环的总计算时间为 53.11 秒,平均值为 531ms
RTX2080 BatchSize 6 FP32
测试代码:
with torch.no_grad():
example_input = torch.rand(1,6,256,256,dtype=torch.float32).to("cuda")
esrganWrapper.eval()
for _ in range(0,2):
out = esrganWrapper(example_input)
start = time.time()
for _ in range(0,25):
out = esrganWrapper(example_input)
end = time.time()
avg = (end-start)/150
当 BatchSize 为 6 时,显存占用为 7.6GB,已经是 RTX2080 的极限。
150 次循环的总计算时间为 75.54 秒,平均值为 504ms
RTX2080 BatchSize 6 FP16
测试代码同上
150 次循环的总计算时间为 33.2 秒,平均值为 221ms
MacBook Pro 2018
本节使用 Xcode 内置的 CoreML 性能测试工具。
Xcode 使用中位数作为衡量标准,而我们在 RTX2080 上使用的是平均值。
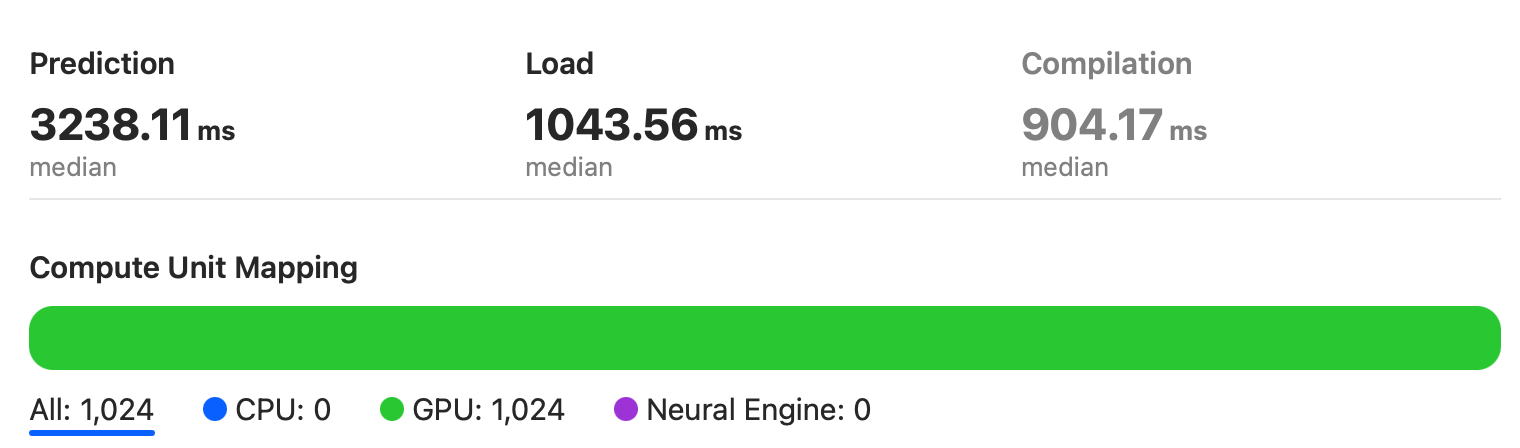
从图中可以看出,模型完全运行在 Intel i5 芯片的集成 GPU 上。
中位数为 3238ms,大约比 RTX2080 慢 6 倍。
Apple GPU(A15)
测试方法与 MacBook 相同。
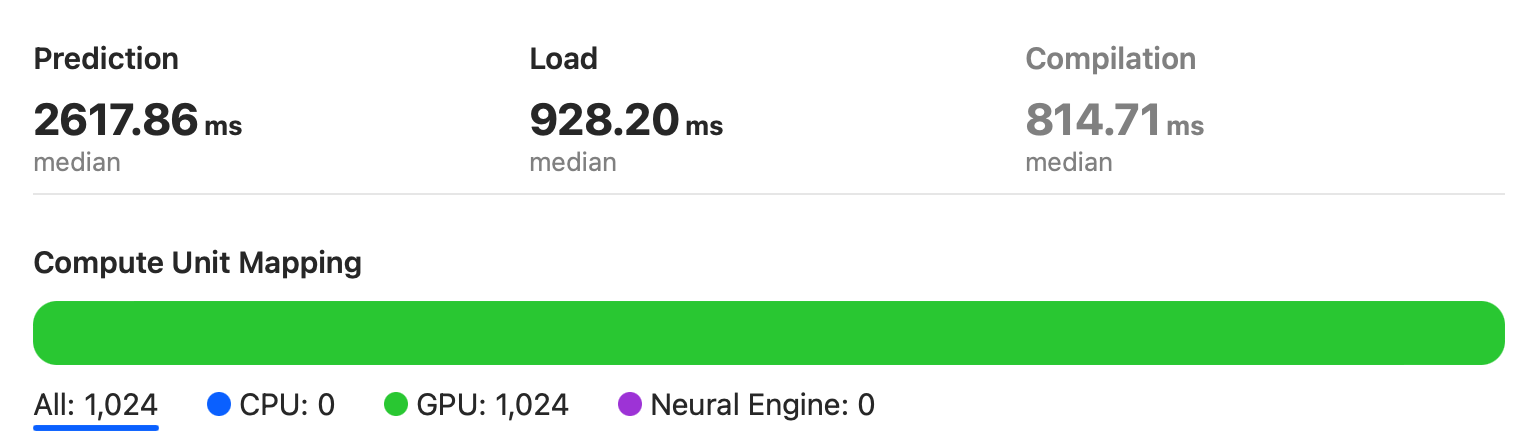
从图中可以看出,模型完全运行在 A15 芯片的 Apple GPU 上。
中位数为 2618ms,大约比 RTX2080 慢 5 倍。不过仍然比搭载 Intel Iris Plus Graphics 655 GPU 的 MacBook 2018 要快。
Apple Neural Engine(A15)
终于要测试我们的主角了,希望它不会让我们失望。 测试方法同上,只是将计算单元限制为 CPU 和 Neural Engine。
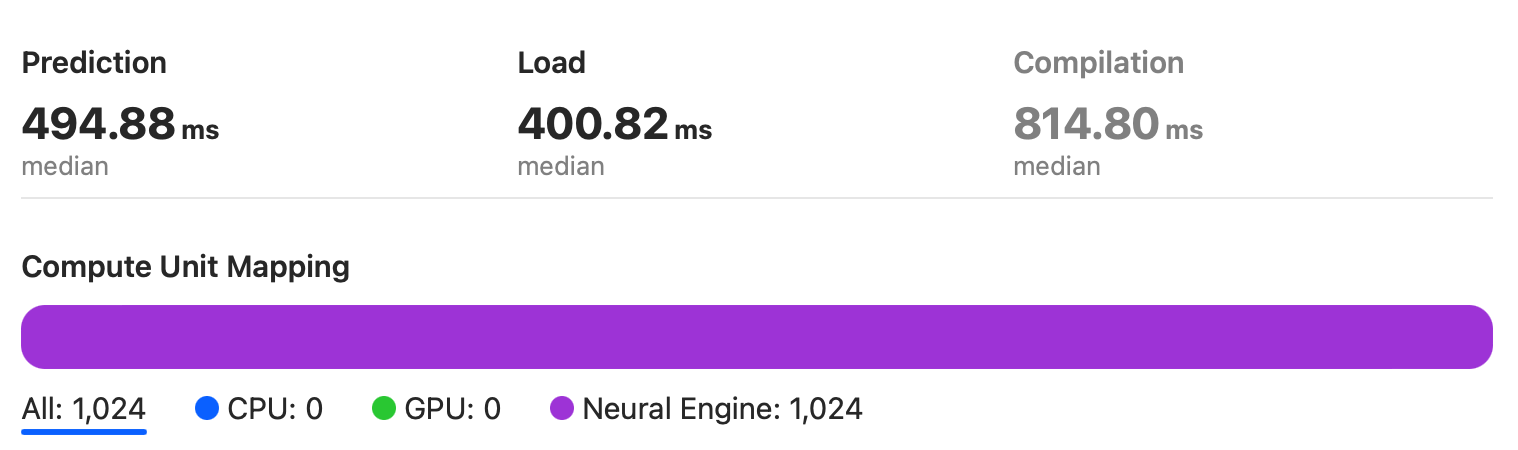
从图中可以看出,模型完全运行在 A15 芯片的 Neural Engine 上。 最终 Apple Neural Engine 没有让我们失望,甚至比 RTX2080 10.07 TFLOPS FP32 还快一些。 中位数为 495ms,比 RTX2080 FP32 快了 36ms!
3. 结论
Apple Neural Engine 的性能没有让我们失望,它甚至比 220W 功耗下的 RTX2080 FP32 还要快。虽然 ANE 的 FP16 没有达到性能预期,但考虑到功耗,ANE 能有这样的表现已经非常令人印象深刻了。
| 设备 | 推理时间 | 相对优势 |
|---|---|---|
| RTX2080 BS=1 FP32 | 531 ms | 0% |
| RTX2080 BS=6 FP32 | 504 ms | 5.1% |
| RTX2080 BS=6 FP16 | 221 ms | 58.3% |
| Intel Iris Plus 655 | 3238 ms | -510% |
| A15 GPU | 2618 ms | -393% |
| A15 ANE | 495 ms | +6.7% |
不过 ANE 本身也有不足之处,它不能像 GPU 那样支持所有的网络算子。但作为一个低功耗处理器,它带来的性能表现已经足够惊艳了。