Recently I came across a blog posted by Apple with a picture showing the performance of Apple Neural Engine (ANE).

As an iOS developer and being the tech nerd I am, I was shocked when I saw that Apple stated that the FP16 performance of the A15 can reach close to 16TFLOPS. As a comparison, the FP16 performance of RTX 2070 is 14.93 TFLOPS. I’m curious how the A15 performs in practice and I decided, I better test them out.
1.Comparing Apple Neural Engine(A15) against RTX 2080
| ANE | ANE | RTX2080 |
|---|---|---|
| FP16 | 15.8TFLOPS | 20.14 TFLOPS |
| FP32 | - | 10.07 TFLOPS |
How?
Considering that ANE is specially optimized for Conv Network and I recently used RealESRGAN_x4plus to develop PixAI. I will use RealESRGAN_x4plus for testing.

If you want to experience this model on your phone, you can download it from here.
Model Spec
Real-ESRGAN aims at developing Practical Algorithms for General Image/Video Restoration.
| Model | Total Params | Param Size |
|---|---|---|
| RealESRGAN_x4plus | 16,697,987 | 66.79 MB |
Model Structure
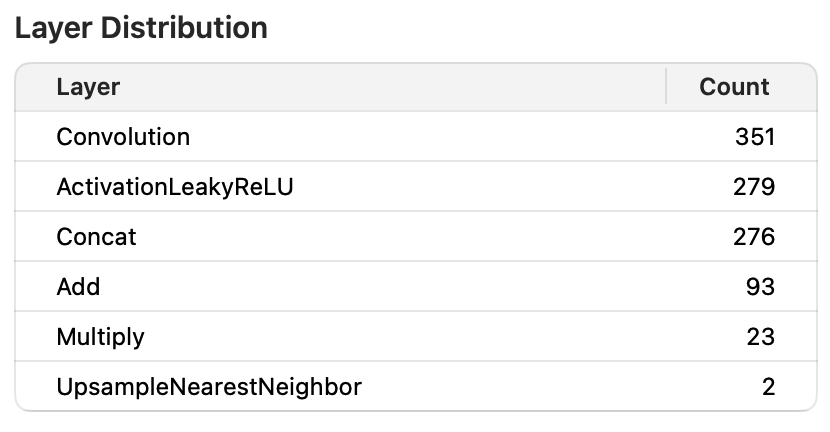
Test method:
- Input: 1 x 3 x 256 x 256 RGB image
- RTX2080: First do 10 inferences to warm up, then loop through 100 inferences and calculate the average inference time
- MacBook Pro 2018 2.3 GHz 4C8T Intel Core i5 with Metal GPU acceleration
- A15 Neural Engine: Test the average inference time using Xcode’s built-in performance testing tools
- A15 Metal GPU: Same as above
So how do the A15 chips go in real world performance?
This article is strictly focused on performance. For design, inputs, outputs, battery life, there’s plenty of other resources out there.
2.Start Testing
RTX2080 BatchSize 1 FP32
Test code:
# First do 10 inferences to warm up, then loop through 100 inferences and calculate the average inference time
with torch.no_grad():
example_input = torch.rand(1,3,256,256,dtype=torch.float32).to("cuda")
esrganWrapper.eval()
for _ in range(0,10):
out = esrganWrapper(example_input)
start = time.time()
for _ in range(0,100):
out = esrganWrapper(example_input)
end = time.time()
avg = (end-start)/100
Here we get 53.11s calculation time for 100 cycles, and the average value is 531ms
RTX2080 BatchSize 6 FP32
Test code:
with torch.no_grad():
example_input = torch.rand(1,6,256,256,dtype=torch.float32).to("cuda")
esrganWrapper.eval()
for _ in range(0,2):
out = esrganWrapper(example_input)
start = time.time()
for _ in range(0,25):
out = esrganWrapper(example_input)
end = time.time()
avg = (end-start)/150
When the BatchSize is 6, the VRAM occupation is 7.6GB, which is already the limit of RTX2080.
Here we get 75.54s calculation time for 150 cycles, and the average value is 504ms
RTX2080 BatchSize 6 FP16
test code is same as above
Here we get 33.2s calculation time for 150 cycles, and the average value is 221ms
MacBook Pro 2018
I use Xcode’s built-in CoreML performance testing tools for this section.
Xcode uses the median as a measure, while we use the average on the RTX2080.
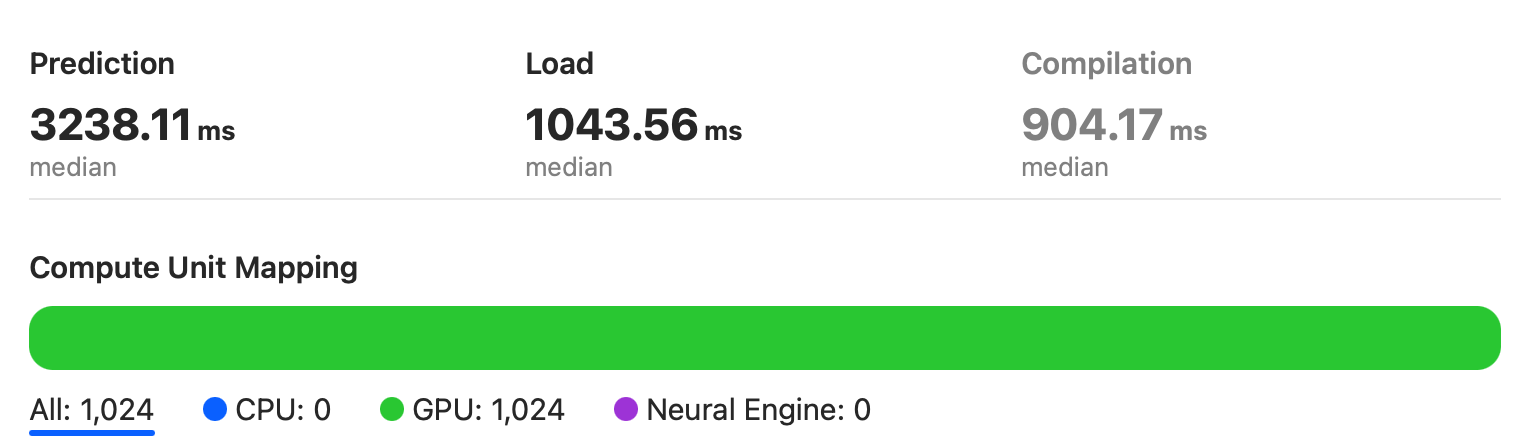
As can be seen from the figure, the model runs entirely on the integrated GPU of the Intel I5 chip.
Here we get the median value is 3238ms, which is about 6 times slower than RTX2080.
Apple GPU (A15)
The test method here is the same as that of the MacBook.
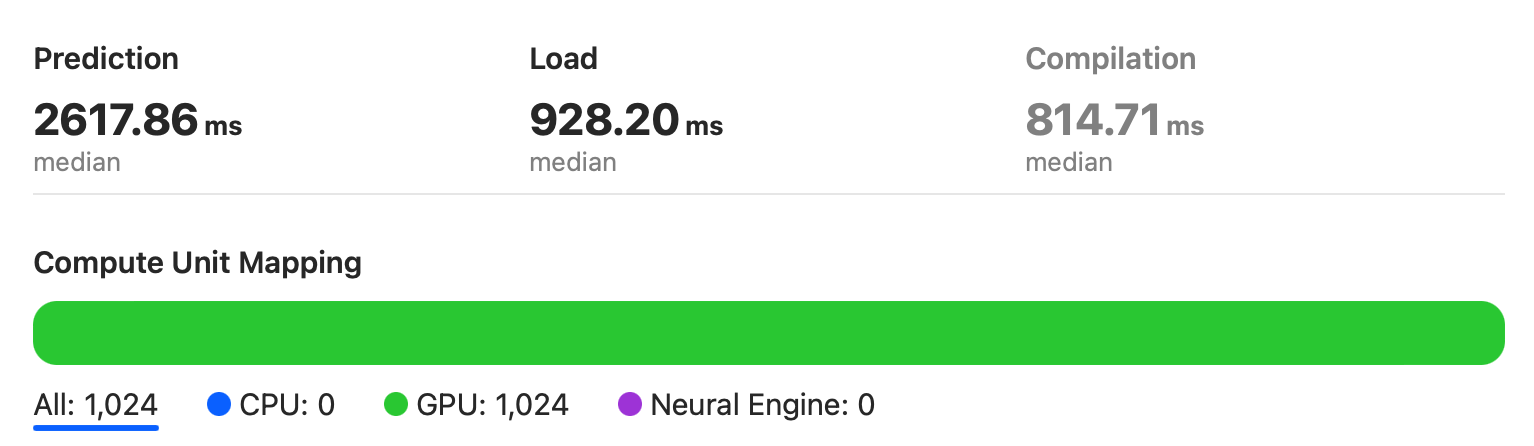
As can be seen from the figure, the model runs entirely on the Apple GPU of the A15 chip.
Here we get the median value is 2618ms, which is about 5 times slower than RTX2080. It’s still faster than a MacBook 2018 though, which has an Intel Iris Plus Graphics 655 GPU.
Apple Neural Engine (A15)
Finally we’re going to test our main character, hope it won’t let us down.
The test method here is the same as above, except that the compute unit is limited to CPU and Neural Engine.
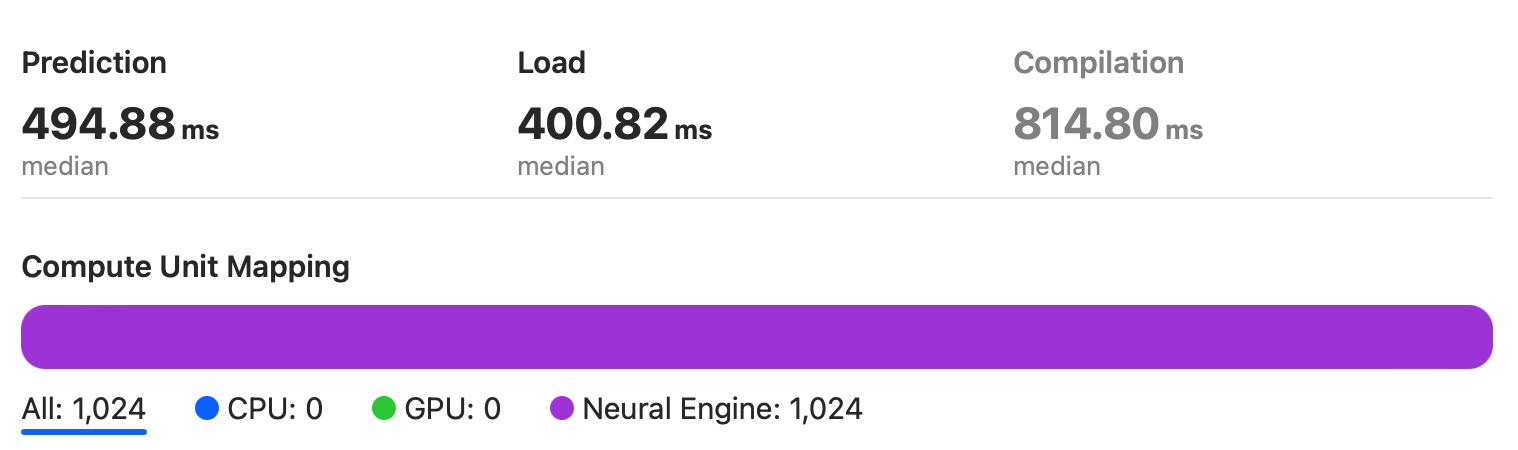
As can be seen from the figure, the model runs entirely on the Neural Engine of the A15 chip.
In the end the Apple Neural Engine doesn’t let us down and is even a bit faster than the RTX2080 10.07 TFLOPS FP32.
Here we get the median value is 495ms, which is 36ms faster than RTX2080 FP32!
3.Conclusion
The performance of Apple Neural Engine did not disappoint us, it is even faster than the RTX2080 at 220W FP32. Although ANE’s FP16 did not meet the performance expectations, considering the power consumption, ANE can have such a performance is very impressive.
| Device | Inference Time | Adv Percentage |
|---|---|---|
| RTX2080 BS=1 FP32 | 531 ms | 0% |
| RTX2080 BS=6 FP32 | 504 ms | 5.1% |
| RTX2080 BS=6 FP16 | 221 ms | 58.3% |
| Intel Iris Plus 655 | 3238 ms | -510% |
| A15 GPU | 2618 ms | -393% |
| A15 ANE | 495 ms | +6.7% |
However, ANE itself also has shortcomings, it cannot support all networks ops like gpu. But as a low-power processor, the performance it brings us is already surprising enough.
Comments